
W Zintegrowanym Rejestrze Kwalifikacji znajdują się najważniejsze informacje o każdej kwalifikacji włączonej do ZSK. Połączenie informacji zawartych w ZRK z innymi, gromadzonymi w ramach projektu zasobami zewnętrznymi pochodzącymi z różnych źródeł, a następnie analiza i ich przetwarzanie umożliwiają wdrożenie rozwiązań usprawniających funkcjonowanie systemu i wspierających interesariuszy. Jednym z głównych celów zespołu Zadania jest więc przetwarzanie dużych zasobów danych tekstowych na potrzeby rozwoju i tworzenia nowych narzędzi informatycznych powiązanych z ZRK, wspierających interesariuszy Zintegrowanego Systemu Kwalifikacji.
Nowe narzędzia w projekcie ZRK2
W projekcie przewidziano cztery główne kierunki działań dla Zadania 5 związanych z wykorzystaniem technik sztucznej inteligencji:
- przygotowanie i uruchomienie narzędzia do automatycznego wspomagania doradztwa opierającego się na zasobach ZRK i portalu ZSK. Narzędzie to powstaje głównie z myślą o doradcach zawodowych, edukacyjnych, dyrektorach szkół, firmach HR i zespołach HR oraz dla użytkowników ZRK (czatbot);
- przygotowanie pierwszej wersji narzędzia ułatwiającego automatyczne wspomaganie opisywania kwalifikacji w języku efektów uczenia się oraz przypisywania poziomu PRK do kwalifikacji;
- opracowanie pierwszej prototypowej wersji aplikacji z zakresu automatycznego wspomagania pracowników działów HR i firm działających w tym obszarze w zakresie tworzenia ogłoszeń o pracę z odwołaniami do ZSK oraz dopasowywane do nich życiorysów;
- działania na rzecz monitorowania i analizowania ofert pracy poprzez budowę narzędzia służącego przede wszystkim do gromadzenia informacji z internetowych ogłoszeń o pracę oraz przetwarzania ich na potrzeby rozpoznania, jakie jest zapotrzebowanie na kwalifikacje i umiejętności w skali kraju.
Monitorojas
Ostatnie z wymienionych narzędzi roboczo nazywamy Monitorojasem (Monitor + OJAs, czyli Online Job Advertisements). Jak wspomnieliśmy, służy ono do zbierania i przetwarzania ofert pracy publikowanych w Internecie. Podstawowym założeniem dotyczącym tej aplikacji jest to, że analiza treści ogłoszeń o pracę i śledzenie w ten sposób aktualnych trendów na rynku pracy pozwolą m.in. wnioskować o obecnym zapotrzebowaniu na umiejętności w kraju oraz o aktualnym stopniu dopasowania oferty systemu kwalifikacji (w tym szkolnictwa branżowego) do potrzeb rynku pracy.
Monitorojas będzie stale monitorował i regularnie pobierał ogłoszenia o pracę opublikowane w wybranych źródłach. Następnie teksty będą przetwarzane przez model AI, którego zadaniem będzie rozpoznanie jednostek pojawiających się w treści ogłoszeń, ich ekstrakcja i strukturyzacja.
NER
Model AI, o którym mowa, to tzw. NER. W uczeniu maszynowym NER (ang. Named Entity Recognition, czyli rozpoznawanie jednostek nazewniczych) jest techniką, która pozwala automatycznie kategoryzować fragmenty tekstu. W szczególności technika ta może być przydatna do identyfikowania, czy dany fragment tekstu oznacza osobę, datę, miejscowość, firmę itp. Przykład działania modelu NER, który został wytrenowany dla języka angielskiego do wyodrębniania takich jednostek, przedstawia rysunek 1.

Na wizualizacji widać, jak w przykładowym tekście model automatycznie wykrył, że wyrażenie „Sebastian Thrun” oznacza osobę, z kolei „Google” – organizację itd. W ten sposób możemy wyekstrahować z tekstu interesujące nas informacje i w odpowiedni sposób je ustrukturyzować i przechowywać w bazie danych.
Przykładem tekstów, które z reguły nie są w pełni ustrukturyzowane, są właśnie internetowe ogłoszenia o pracę. NER trenowany na potrzeby Monitorojasa nie będzie jednak wyszukiwał w nich nazw osób czy miejsc, lecz takie elementy, jak: nazwę stanowiska, na które prowadzona jest rekrutacja, zadania zawodowe, wymagania dotyczące wykształcenia lub doświadczenia, oczekiwania odnoszące się do umiejętności językowych czy oferowane przez firmę pakiety dodatkowych świadczeń dla pracowników itp.
Ontologia umiejętności
W dalszych etapach przetwarzania danych rozpoznane fragmenty tekstu będą identyfikowane jako obiekty w tzw. ontologii umiejętności. Ontologią nazywamy ustrukturyzowany i kontrolowany słownik umiejętności zbierający różne informacje, np. o relacjach umiejętności do kwalifikacji, zawodów, grup zawodów, branż itp. (słownikiem o podobnym charakterze jest np. ESCO). Można myśleć o takim słowniku jako o grafie zbierającym wiedzę, która pomoże AI lepiej rozumieć dane i dostrzegać między nimi nowe zależności.
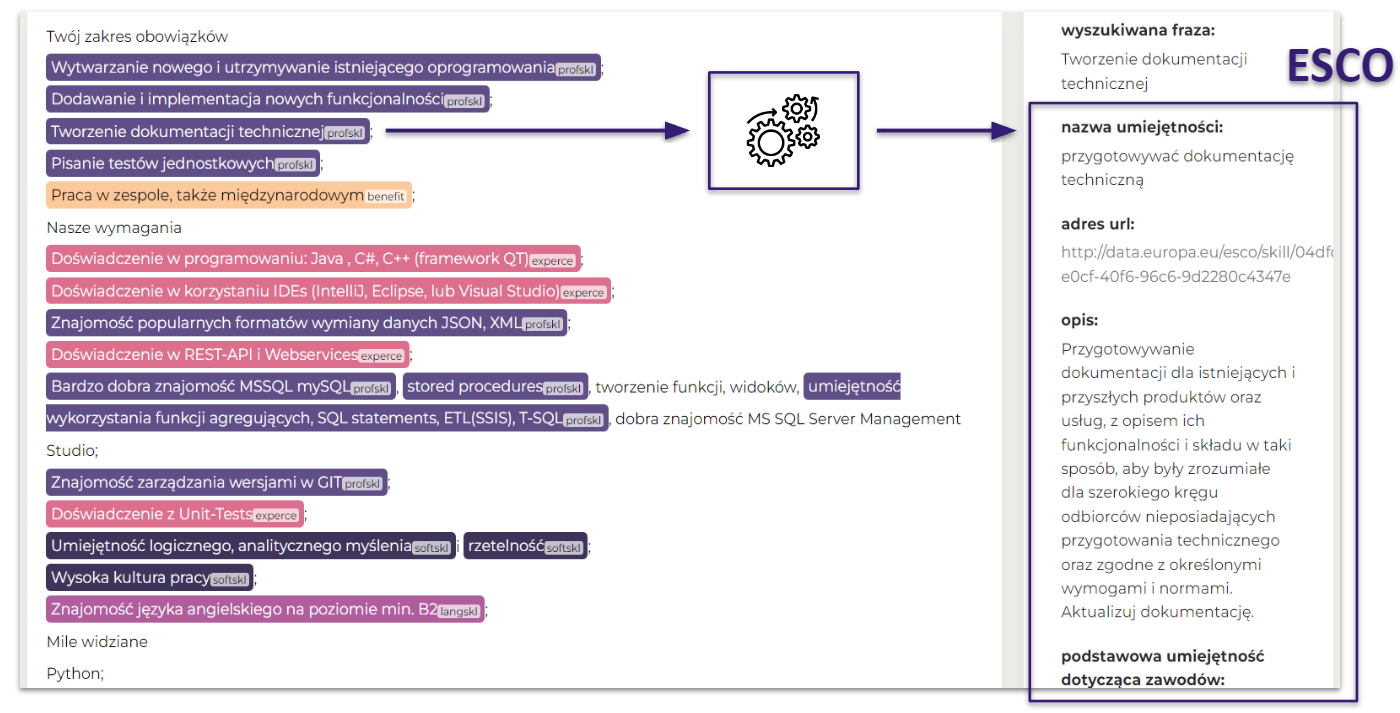
Oczekiwane efekty
Po przejściu opisanych etapów możliwe będzie analizowanie pojedynczych ogłoszeń pod kątem zawartych w nich informacji oraz tworzenie zestawień statystycznych dotyczących poszukiwanych umiejętności w różnorodnych przekrojach. Mogą one przyczynić się m.in do lepszego zrozumienia aktualnych trendów na rynku pracy (np. zmian w liczbie wakatów w sektorach, zainteresowaniu osobami z określonymi umiejętnościami), szybszego reagowania na zmiany dotyczące zapotrzebowania na pracowników oraz wybrane umiejętności, inicjowania działań na rzecz nabywania umiejętności potrzebnych na rynku, a nieujętych w kwalifikacjach funkcjonujących w ZSK (dopasowanie systemu kwalifikacji do rynku ofert o pracę). Dodatkowo informacje z ogłoszeń, po odpowiedniej obróbce, mogą posłużyć także do wielu innych celów, np. do tworzenia ogłoszeń o pracę, przygotowania CV lub szukania stopnia dopasowania treści ogłoszenia do treści złożonych CV.
Prace nad narzędziami potrwają do września 2023 roku. Stay tuned 🙂
O autorach:
Leopold Będkowski – od 2019 roku zatrudniony w IBE w projekcie ZRK. W ZRK2 ekspert ds. lingwistyki obliczeniowej/Data Scientist.
Dr Marcin Będkowski – od 2019 roku zatrudniony w IBE w projekcie ZRK. W ZRK 2 ekspert główny ds. lingwistyki obliczeniowej/Data Scientist. Pracownik dydaktyczno-naukowy na Wydziale Polonistyki Uniwersytetu Warszawskiego, kierownik Zakładu Językoznawstwa Komputerowego.
Agata Niedolistek-Halicka – od 2018 roku zatrudniona w IBE w projekcie ZRK. W ZRK 2 pełni funkcję eksperta kluczowego zadania, w ramach którego prowadzone są prace w zakresie narzędzi opartych o sztuczną inteligencję. Od marca 2022 roku wicelider projektu ZRK2.




